본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
*_1. 학습 인증샷 4장 이상 포함
*_① 오늘자 날짜, 공부 시작 시각 포함 사진 1장

② 오늘자 날짜, 공부 종료 시각 포함 사진 1장

③ 1개 클립 수강 인증 사진 (강의장 목록 캡쳐, 강의 내용이 담긴 수강화면이 보이지 않도록) 1장

④ 학습 인증샷 1장 이상 (ex. 필기 촬영, 작업물, 등)
2. 학습 후기 700자 이상 (공백 제외)
허깅페이스
- 데이터 로드
urllib.request.urlretrieve("[https://raw.githubusercontent.com/ukairia777/tensorflow-nlp-tutorial/main/10.%20RNN%20Text%20Classification/dataset/naver\_shopping.txt"](https://raw.githubusercontent.com/ukairia777/tensorflow-nlp-tutorial/main/10.%20RNN%20Text%20Classification/dataset/naver_shopping.txt"), filename="naver\_shopping.txt")- 훈련데이터와 테스트 데이터 분리
- 분리
total\_data\['label'\] = np.select(\[total\_data.ratings > 3\], \[1\], default=0) total\_data\[:5\]- 중복카운트
total\_data\['ratings'\].nunique(), total\_data\['reviews'\].nunique(), total\_data\['label'\].nunique()
- 레이블 분포 확인
train_data['label'].value_counts().plot(kind = 'bar')- 실전 모델링 (감성분류)
from transformers import pipeline
classifier = pipeline("text-classification", model="matthewburke/korean_sentiment")
custom_tweet = "영화 재밌다."
preds = classifier(custom_tweet, return_all_scores=True)
is_positive = preds[0][1]['score'] > 0.5
print('스코어 점수 확인 :', preds[0][1]['score'])
print('긍정 여부 :', is_positive)
테스트 데이터 중 상위 1,000개만 복사
test_data_for_sample = test_data[:1000].copy()
정확도 계산 함수
def compute_accuracy(df):
correct = (df['pred'] == df['label']).sum()
total = len(df)
return correct / total
acc = compute_accuracy(test_data_for_sample)
print('정확도(%):', acc * 100)
- 실전 모델링 (텍스트 요약기)
~~~~ 텍스트 요약기 코드
import nltk
nltk.download('punkt')
nltk.download('punkt_tab')
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained('eenzeenee/t5-base-korean-summarization')
tokenizer = AutoTokenizer.from_pretrained('eenzeenee/t5-base-korean-summarization')
prefix = "summarize: "
sample = """
안녕하세요? 우리 (2학년)/(이 학년) 친구들 우리 친구들 학교에 가서 진짜 (2학년)/(이 학년) 이 되고 싶었는데 학교에 못 가고 있어서 답답하죠?
그래도 우리 친구들의 안전과 건강이 최우선이니까요 오늘부터 선생님이랑 매일 매일 국어 여행을 떠나보도록 해요.
어/ 시간이 벌써 이렇게 됐나요? 늦었어요. 늦었어요. 빨리 국어 여행을 떠나야 돼요.
그런데 어/ 국어여행을 떠나기 전에 우리가 준비물을 챙겨야 되겠죠? 국어 여행을 떠날 준비물, 교안을 어떻게 받을 수 있는지 선생님이 설명을 해줄게요.
(EBS)/(이비에스) 초등을 검색해서 들어가면요 첫화면이 이렇게 나와요.
자/ 그러면요 여기 (X)/(엑스) 눌러주(고요)/(구요). 저기 (동그라미)/(똥그라미) (EBS)/(이비에스) (2주)/(이 주) 라이브특강이라고 되어있죠?
거기를 바로 가기를 누릅니다. 자/ (누르면요)/(눌르면요). 어떻게 되냐? b/ 밑으로 내려요 내려요 내려요 쭉 내려요.
우리 몇 학년이죠? 아/ (2학년)/(이 학년) 이죠 (2학년)/(이 학년)의 무슨 과목? 국어.
이번주는 (1주)/(일 주) 차니까요 여기 교안. 다음주는 여기서 다운을 받으면 돼요.
이 교안을 클릭을 하면, 짜잔/. 이렇게 교재가 나옵니다 .이 교안을 (다운)/(따운)받아서 우리 국어여행을 떠날 수가 있어요.
그럼 우리 진짜로 국어 여행을 한번 떠나보도록 해요? 국어여행 출발. 자/ (1단원)/(일 단원) 제목이 뭔가요? 한번 찾아봐요.
시를 즐겨요 에요. 그냥 시를 읽어요 가 아니에요. 시를 즐겨야 돼요 즐겨야 돼. 어떻게 즐길까? 일단은 내내 시를 즐기는 방법에 대해서 공부를 할 건데요.
그럼 오늘은요 어떻게 즐길까요? 오늘 공부할 내용은요 시를 여러 가지 방법으로 읽기를 공부할겁니다.
어떻게 여러가지 방법으로 읽을까 우리 공부해 보도록 해요. 오늘의 시 나와라 짜잔/! 시가 나왔습니다 시의 제목이 뭔가요? 다툰 날이에요 다툰 날.
누구랑 다퉜나 동생이랑 다퉜나 언니랑 친구랑? 누구랑 다퉜는지 선생님이 시를 읽어 줄 테니까 한번 생각을 해보도록 해요."""
inputs = [prefix + sample]
inputs = tokenizer(inputs, max_length=512, truncation=True, return_tensors="pt")
output = model.generate(**inputs, num_beams=3, do_sample=True, min_length=10, max_length=64)
decoded_output = tokenizer.batch_decode(output, skip_special_tokens=True)[0]
result = nltk.sent_tokenize(decoded_output.strip())[0]
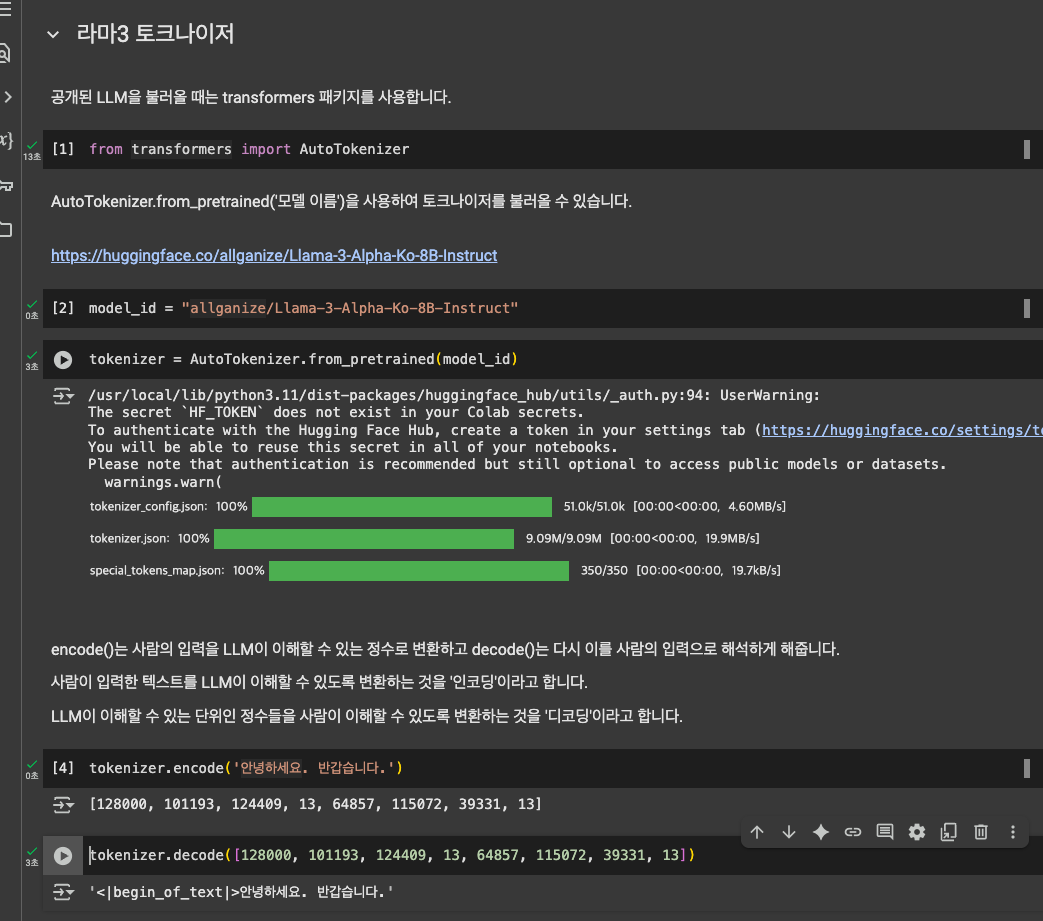
print('RESULT >>', result)토크나이저
from transformers import AutoTokenizer
model_id = "allganize/Llama-3-Alpha-Ko-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)- allganize 모델에서 가져온 토크나이저는 반드시 동일한 모델에서 사용해야 함
- 모델마다 어떤 토큰에 맵핑되는 정수가 다 다르기 때문
템플릿
- 보통 LLM이 학습됐을 당시의 템플릿을 개발자가 공개하는 편임
- 그러나, 그걸 하나하나 따르기 귀찮을 경우, 템플릿을 자동으로 처리하는 방법이 허깅페이스 토크나이저에 있음
template_messages = tokenizer.apply_chat_template(messages, tokenize=False) print(template_messages)<|begin_of_text|><|start_header_id|>system<|end_header_id|>
당신은 패스트캠퍼스의 대표 LLM 패캠이입니다.<|eot_id|><|start_header_id|>user<|end_header_id|>
은행의 기준 금리에 대해서 설명해줘<|eot_id|>
- tokenizer=True를 사용하면 템플릿 적용 및 정수 인코딩 후의 결과를 볼 수 있음
~~~~ 토크나이저 트루 코드
encodeds = tokenizer.apply_chat_template(messages)
print('템플릿 적용 및 정수 인코딩 후:\n', encodeds)
print('--' * 100)
print('템플릿 적용 및 정수 인코딩 결과를 복원:\n',tokenizer.decode((encodeds)))어시스턴트 시작점
- LLM 답변 바로 직전의 프롬프트까지 추가해야함
e.g. <|begin_of_text|><|start_header_id|>system<|end_header_id|>
당신은 패스트캠퍼스 챗봇 패캠이입니다. 묻는 말에 친절하고 정확하게 답변하세요.<|eot_id|><|start_header_id|>user<|end_header_id|>
당신이 누군지 설명해주십시오<|eot_id|><|start_header_id|>
assitant 문장 나오기 직전까지 input으로 넣어줘야 됨.
url : https://abit.ly/lisbva
'스타트업 투자 > 데이터 + 테크' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 10일차 : RAG (0) | 2025.04.10 |
|---|---|
| 패스트캠퍼스 환급챌린지 9일차 : 파인튜닝 (0) | 2025.04.09 |
| 패스트캠퍼스 환급챌린지 7일차 : ChatGPT API를 이용한 데이터 생성 (0) | 2025.04.07 |
| 패스트캠퍼스 환급챌린지 6일차 : 프롬프트 엔지니어링 (0) | 2025.04.06 |
| 패스트캠퍼스 환급챌린지 5일차 : 인코더와 디코더가 문제를 푸는 방식 (1) | 2025.04.05 |




댓글